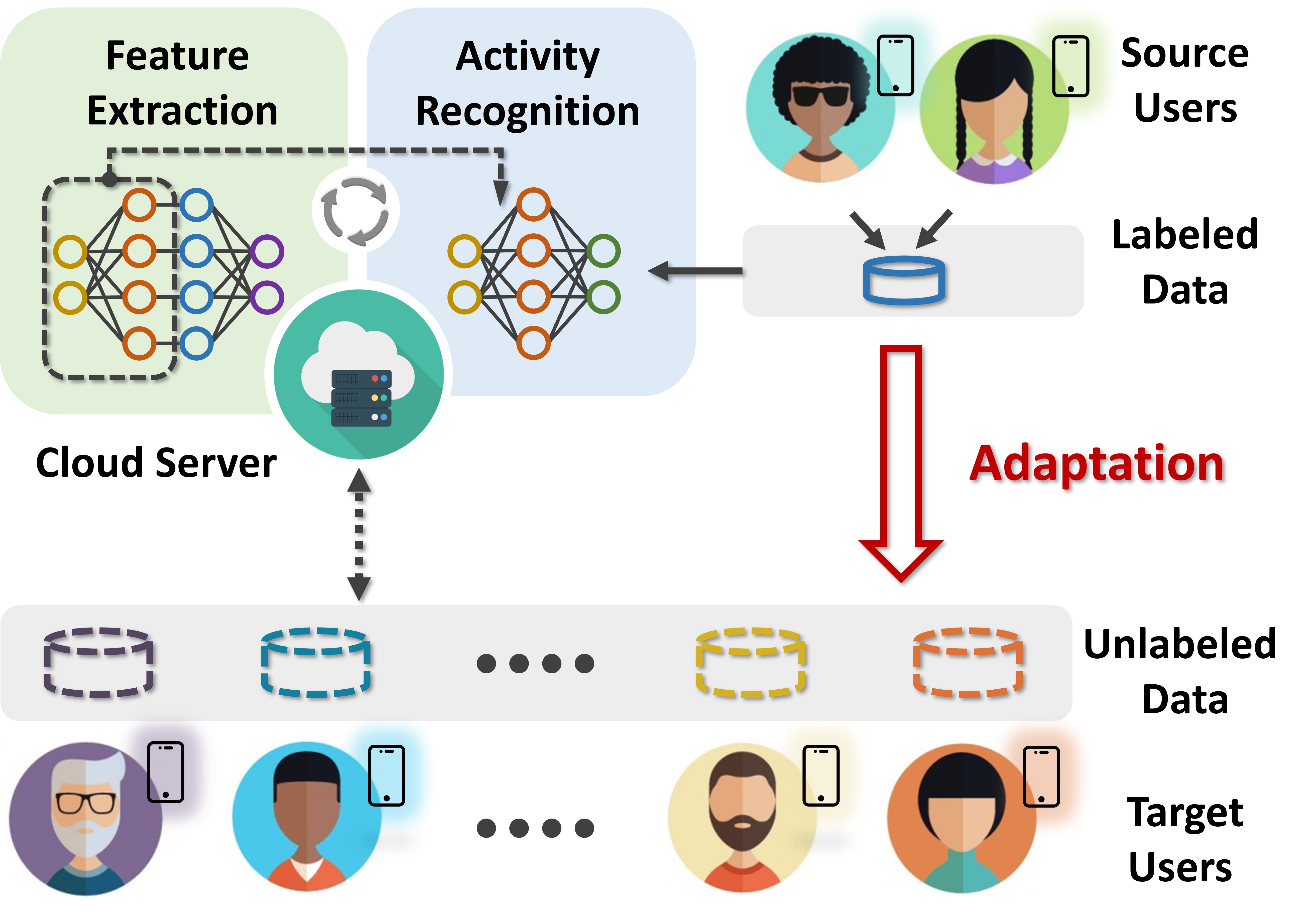
Can we have a universal framework that supports applying human activity recognition (HAR) models across different user groups of real-world diversities, and with realistic adoption overhead?
We present UniHAR, a universal HAR framework for mobile devices. To address the challenge of data heterogeneity, we thoroughly study augmenting data with the physics of the IMU sensing process and present a novel adoption of data augmentations for the feature learning.
UniHAR is fully prototyped on the mobile platform and introduces low overhead to mobile devices. Extensive comparative experiments demonstrate its superior performance in adapting HAR models across four open datasets.
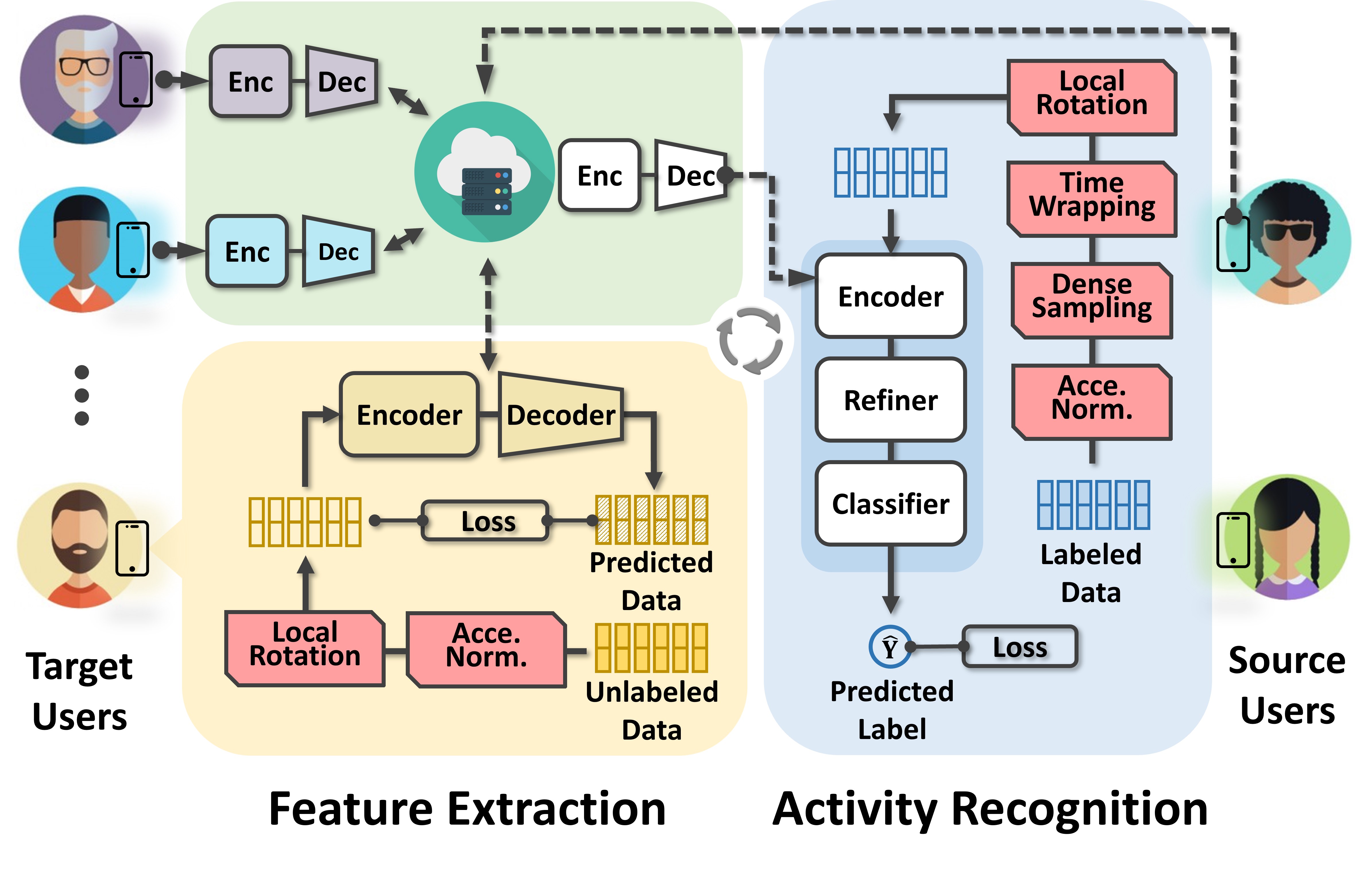
UniHAR has two training stages:
Feature Extraction. All local unlabeled datasets are first augmented to align the distributions of heterogeneous data from various clients. To construct a generalized feature extractor (i.e., the encoder), the cloud server collaborates with all mobile clients to exploit massive augmented unlabeled data. The encoder and decoder are trained on clients individually, which learn the high-level features using self-supervised learning techniques. The cloud server combines local models and obtains a generalized model.
Activity Recognition. Based on the generalized encoder, the server then adopts a small amount of labeled data from source users and trains an activity recognition model. Data augmentation is also integrated to enrich the diversity of labeled data and narrow the distribution gap between the source and target domains. The activity recognizer, including encoder, refiner, and classifier, jointly learn to recognize activity types of labeled IMU data.
After the server dispatches the recognizer, each client utilizes it to classify activities without additional training.
To mitigate the data heterogeneity, UniHAR enriches the IMU data diversity based on physical knowledge and assists the learning of generalizable features.
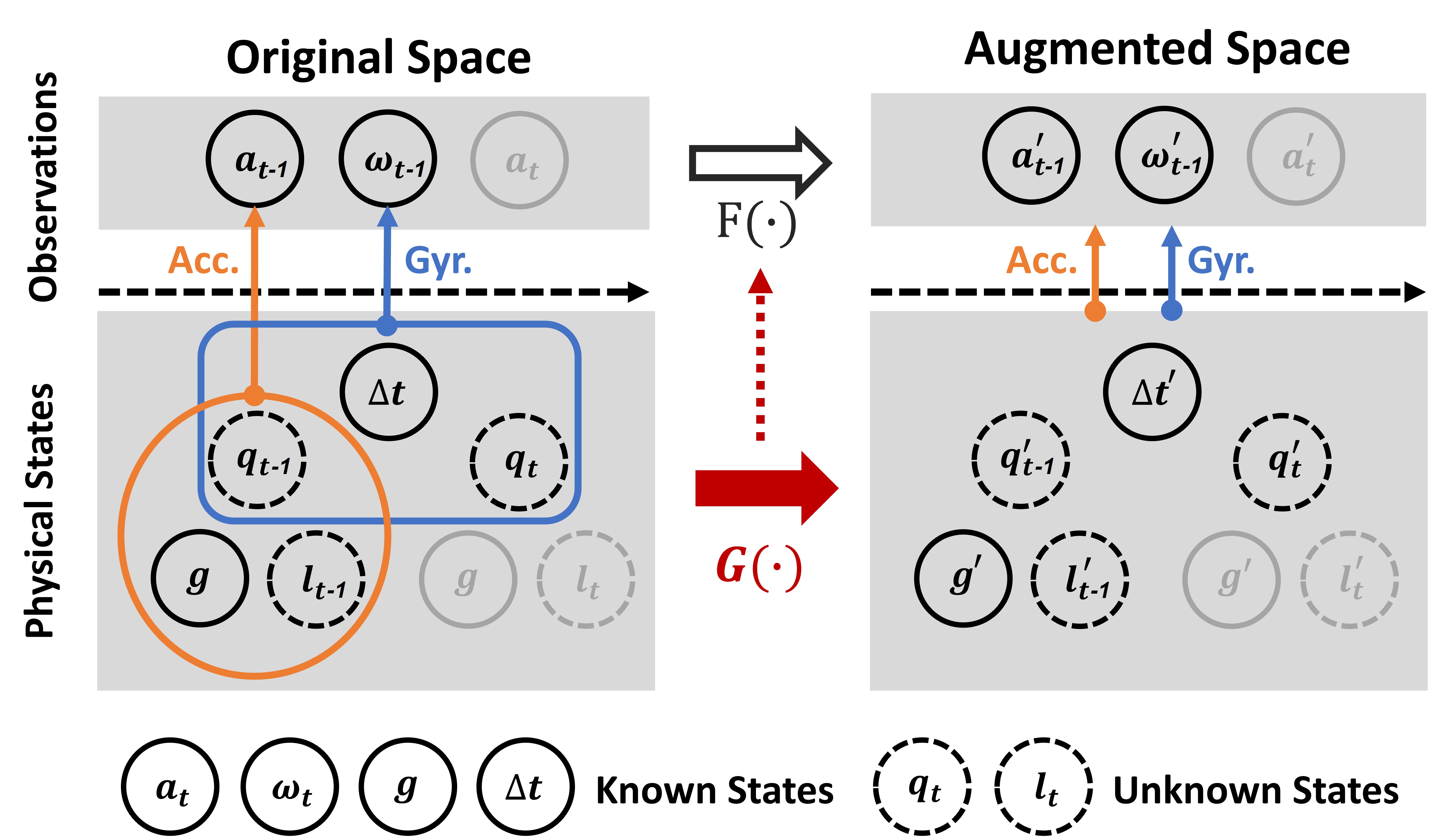
Sensor readings are observations from the underlying physical states. A data augmentation is a mapping F(·) that transforms observations from the original space to the augmented space. We introduce the concept of physical embedding G(·) to align the mapping F(·) between observations with the underlying physical principles, which is defined as:
"G(·) is a physical embedding of F(·) if G(·) transforms physical states such that the observations from the transformed physical states equal the augmented observations of F(·). "
In practice, a mapping F(·) that has a physical embedding G(·) indicates the transition of readings can take place through a physical process in reality. We thus define three types of data augmentation based on the above physical embedding:
Complete data augmentation, where its mapping F(·) is connected with a physical embedding G(·), and F(·) can be fully formulated with original observations and known physical states.
Approximate data augmentation, where its mapping F(·) is connected with a physical embedding G(·), but F(·) involves unknown physical states and can be approximated by a formulation of known states.
Flaky data augmentation, where we cannot find a physical embedding G(·) to support its mapping F(·).
We refer complete and approximate data augmentations to Physics-Informed Data Augmentations (PIDA), which both have underlying support of physical embeddings.
UniHAR incorporates physics-informed data augmentation methods differently during the two stages of the framework based on their respective characteristics. During the feature extraction stage, UniHAR only employs complete data augmentations to unlabeled data for generalizing the data distributions and avoiding approximation errors at scale. During the feature extraction stage, UniHAR applies both complete and approximate data augmentation to augment labeled data for further data representativeness.
In practical applications, UniHAR is a configurable framework that can adapt to two scenarios, i.e., data-decentralized and data-centralized scenarios.
In the data-decentralized scenario where raw data transmission is not encouraged, UniHAR collaborates with all users and integrates self-supervised and federated learning techniques to train a generalized feature extraction model using massive and augmented unlabeled data. UniHAR then constructs an activity recognition model using limited but augmented labeled data from source users.
In the data-centralized scenario, where raw data transmissions from target users are possible, UniHAR can further leverage adversarial training techniques for improved performance.
Check UniHAR paper for more details.
Check UniHAR if you are interested in implementing UniHAR with Pytorch.
Check UniHAR Mobile if you are interested in building HAR models on Android devices with Tensorflow lite.
Check our previous work LIMU-BERT (an IMU foundation model) if you are interested in self-supervised representation learning for IMU data.
@inproceedings{xu2023practically,
title={Practically Adopting Human Activity Recognition},
author={Xu, Huatao and Zhou, Pengfei and Tan, Rui and Li, Mo},
booktitle={Proceedings of the 29th Annual International Conference on Mobile Computing and Networking},
pages={1--15},
year={2023}
}